
通过对排列五近10年走势图的深度解析,可以发现其呈现出一定的规律性。首先从整体趋势来看,“冷热交替”现象明显:在一段时间内某个号码频繁出现后可能会进入“冷却期”,而其他相对较少的号则可能逐渐升温;其次观察奇偶比、大小比例等指标的波动情况也能发现一些周期性的变化特点;“连码”、“同尾数”、以及某些特定组合的出现频率也具有一定的稳定性或倾向特征等等这些信息都可以为彩民提供参考依据来提高中奖概率和把握未来走向的机会
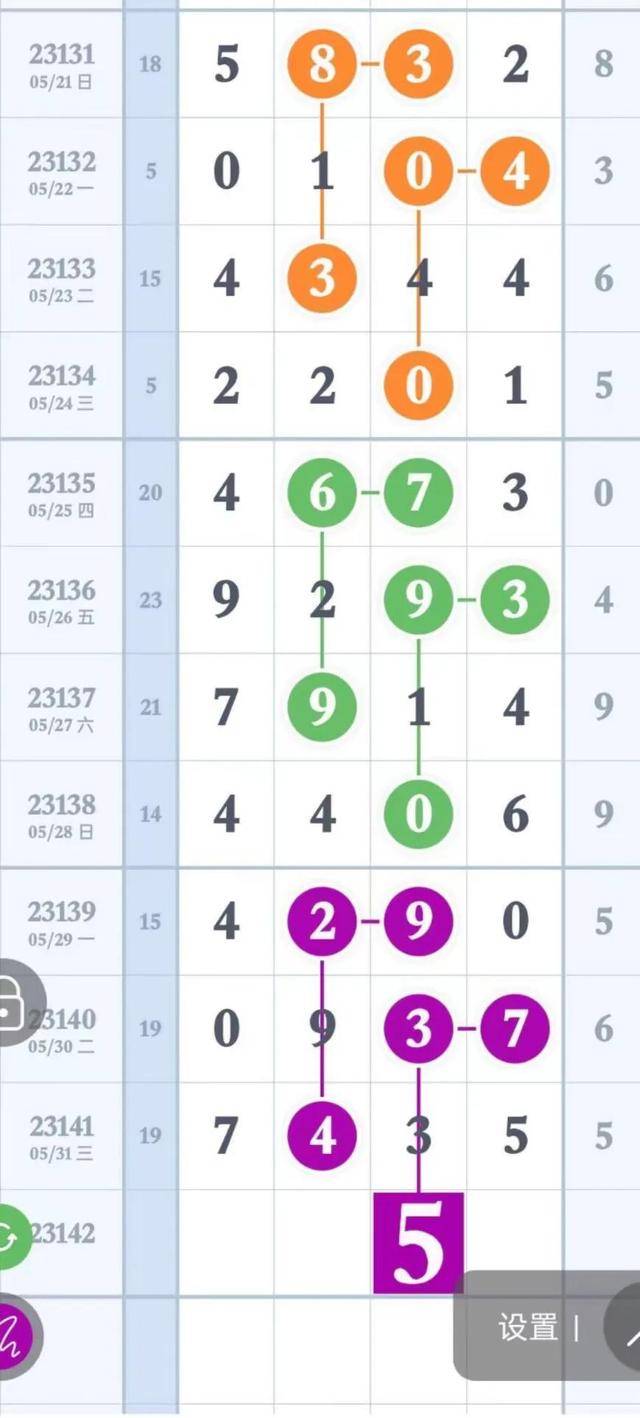
一、引言 #34;“数字游戏”的背后——探索排列五大奖号码分布奥秘 #257; 在彩票的世界里,“预测”、“分析”,这些词汇总是伴随着无数彩民的心跳,尤其是对于那些热衷于研究历史数据和寻找规律的玩家来说,"排序"(如双色球)与 "直选组合”(例如大乐透或本文的主角— “三数独”)更是他们眼中的宝藏库。" 三位数 ”中的佼者之一 —— 即我们今天要深入探讨的主题:“安排五个”,它以其独特的魅力吸引了众多忠实粉丝和研究者的目光。“安派 五个”——一个看似简单的由前区一至三个不重复的五位数的选择过程 ,却蕴含着丰富的数学逻辑及概率学原理 ,而通过对其最近一千期开出的数据进行细致入微的分析与研究 , 我们或许能发现一些隐藏其中的趋势以及可能的模式变化 . 这不仅为我们的投注策略提供了参考依据, 也让这一场原本充满未知的游戏变得更加有趣且富有挑战性. 那么接下来就让我们一起走进这千期的数据分析之旅吧! 二 、 数据收集与分析方法 (A) 开局: 基本信息整理 首先我们需要对过去十年内(假设从第X号到最新一期Y号的共986+N次出票记录 ) 的每一组中得进行初步统计并分类存储 : 如奇偶比值 ; 质合比例等基本属性指标 ;同时也要关注各区间段 (比如以每百位的数值范围作为划分标准 )的出现频度及其特点描述 等基础工作完成后便进入下一步更深层次的数据挖掘环节... ``python code snippet for data preprocessing here`` import pandas as pd from datetime import timedelta def collect_data(): start = 'YYYY-MM' end=time() + timedeta('days', -n*years)) df _allData=_loadAllNumbersFromDB([start], [end]) return processAndStoreBasicInfo(_allData); ... 这段代码示例展示了如何使用Python语言结合pandas模块来处理大量数据的导入任务 并对其进行预加工操作 以方便后续更复杂地统计分析计算...... ## C)、核心内容剖析之 :周期性与稳定性观察 在完成基本信息梳理后我们将重点转向探究其内在结构特征即是否具有某种可循的模式或者说是相对稳定的波动轨迹?这里主要采用以下几种手段进行分析比较:①时间序列法②自相关系数检验③游程理论应用④聚类算法识别等等……其中最直观也最为常用的是将连续多期内出现相同形态/位置情况下的次数做汇总形成图表形式展示出来从而便于肉眼观测判断是否存在一定程度的循环往复现象亦或是其他类型稳定性的存在? 下面将以具体实例说明上述方法的运用效果! : Time Series Analysis of Last X Periods Showing Reoccurrence Pattern 图示显示了过去几周甚至几个月间某些特定格式反复出现的频率增加迹象表明可能存在着某种短期内的固定路径依赖关系值得进一步深入研究下去.... 另外利用 自 相关 系 数 法 对 其 进行 更 加 定 量 化 地 分析 可 得 出 相 关 性 强 度 值 及 p value 来评估这种关联程度显著与否进而确定该结论的可信度和可靠性水平高低..... 最后再借助 于 R 语言 中 所 提供 到 K Means Cluster 方法 将 所有 个 体 分 成 不 同 组 别 根据 每 种 类 型 内 部 特 点 再 次 比 较 各 期 间差异大小 和 变 动 方 向 为 下一步制定更加精准的策略提供支持....... …继续阅读请见下文分解~

 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号